Груписање или анализа кластера је техника машинског учења, која групише неозначени скуп података. Може се дефинисати као „Начин груписања тачака података у различите кластере, који се састоје од сличних тачака података. Објекти са могућим сличностима остају у групи која има мање или никакве сличности са другом групом.'
То ради проналажењем неких сличних образаца у неозначеном скупу података, као што су облик, величина, боја, понашање, итд., и дели их према присуству и одсуству тих сличних образаца.
То је учење без надзора метод, стога алгоритам није обезбеђен надзором, а он се бави неозначеним скупом података.
Након примене ове технике груписања, сваки кластер или група добијају ИД кластера. МЛ систем може да користи овај ИД да поједностави обраду великих и сложених скупова података.
јава арраилист методе
Техника груписања се обично користи за статистичка анализа података.
Напомена: Груписање је негде слично као класификациони алгоритам , али разлика је у типу скупа података који користимо. У класификацији радимо са означеним скупом података, док у груписању радимо са неозначеним скупом података.
Пример : Хајде да разумемо технику груписања са примером тржног центра из стварног света: Када посетимо било који тржни центар, можемо приметити да су ствари са сличном употребом груписане заједно. Као што су мајице груписане у једном делу, а панталоне у другим одељцима, слично, у одељцима за поврће, јабуке, банане, манго итд., груписане су у посебне одељке, тако да можемо лако да сазнамо ствари. Техника груписања такође функционише на исти начин. Други примери груписања су груписање докумената према теми.
Техника груписања може се широко користити у различитим задацима. Неке од најчешћих употреба ове технике су:
- Сегментација тржишта
- Статистичка анализа података
- Анализа друштвених мрежа
- Сегментација слике
- Откривање аномалија итд.
Осим ових општих употреба, користе га Амазон у свом систему препорука да пружи препоруке према претходном претраживању производа. Нетфлик такође користи ову технику да својим корисницима препоручи филмове и веб серије према историји гледања.
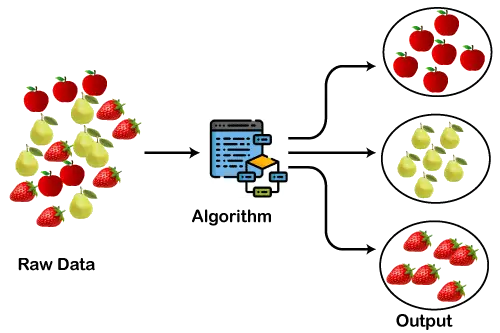
Доњи дијаграм објашњава рад алгоритма за груписање. Можемо видети да су различити плодови подељени у неколико група са сличним својствима.
Врсте метода груписања
Методе груписања су широко подељене на Тешко груписање (тачка података припада само једној групи) и Софт Цлустеринг (тачке података такође могу припадати другој групи). Али постоје и други различити приступи груписања. Испод су главне методе груписања које се користе у машинском учењу:
случајни ц
Партиционисање кластера
То је врста груписања која дели податке у нехијерархијске групе. Такође је познат као метода заснована на центроиду . Најчешћи пример партиционисања кластера је К-Меанс алгоритам груписања .
У овом типу, скуп података је подељен на скуп од к група, где се К користи за дефинисање броја унапред дефинисаних група. Центар кластера је креиран на такав начин да је растојање између тачака података једног кластера минимално у поређењу са средиштем другог кластера.
колико нула у 1 милијарди

Груписање засновано на густини
Метода груписања заснована на густини повезује области велике густине у кластере, а дистрибуције произвољног облика се формирају све док се густи регион може повезати. Овај алгоритам то ради тако што идентификује различите кластере у скупу података и повезује области велике густине у кластере. Густе области у простору података подељене су једна од друге ређим областима.
Ови алгоритми се могу суочити са потешкоћама у груписању тачака података ако скуп података има различите густине и велике димензије.

Кластерисање засновано на моделу дистрибуције
У методи груписања заснованог на моделу дистрибуције, подаци се деле на основу вероватноће како скуп података припада одређеној дистрибуцији. Груписање се врши претпоставком да су неке дистрибуције уобичајене Гауссиан Дистрибутион .
Пример овог типа је Алгоритам кластера очекивања-максимизације који користи моделе Гаусове мешавине (ГММ).

Хијерархијско груписање
Хијерархијско груписање се може користити као алтернатива за партиционисано груписање јер не постоји захтев за унапред специфицирањем броја кластера који ће се креирати. У овој техници, скуп података је подељен у кластере да би се створила структура налик стаблу, која се такође назива а дендрограм . Запажања или било који број кластера се могу изабрати сечењем дрвета на одговарајућем нивоу. Најчешћи пример ове методе је Агломеративни хијерархијски алгоритам .

Фуззи Цлустеринг
Фази кластерисање је врста меке методе у којој објекат података може припадати више од једне групе или кластера. Сваки скуп података има скуп коефицијената чланства, који зависе од степена чланства у кластеру. Фуззи Ц-меанс алгоритам је пример ове врсте груписања; понекад је познат и као алгоритам Фуззи к-меанс.
амрита рао глумац
Алгоритми груписања
Алгоритми груписања се могу поделити на основу њихових модела који су објашњени изнад. Објављени су различити типови алгоритама за груписање, али само неколико се обично користе. Алгоритам груписања је заснован на врсти података које користимо. На пример, неки алгоритми треба да погоде број кластера у датом скупу података, док се од неких захтева да пронађу минималну удаљеност између посматрања скупа података.
Овде говоримо о углавном популарним алгоритмима груписања који се широко користе у машинском учењу:
Примене груписања
Испод су неке опште познате примене технике груписања у машинском учењу: